
前言
这是一门由MIT的Robert Morris主讲的分布式系统课程,课程主页链接,课程视频链接
课程内容包括Golang的学习、分布式系统研究动机、一致性协议算法、著名分布式系统软件论文讲解和一致性算法 (Raft算法)的实现机制及实验。
是一门不可多得的实践性质比较强的课程。
本文主要记录自己做lab时候的一些心得体会,以及对课程的一些理解。
Lab1:MapReduce
论文:MapReduce: Simplified Data Processing on Large Clusters
Lab链接:Lab1
设计思路
MapReduce是一个分布式计算框架,它的设计思路是将计算任务分为两个阶段:Map阶段和Reduce阶段。
这是MapReduce的一个简单的示意图:
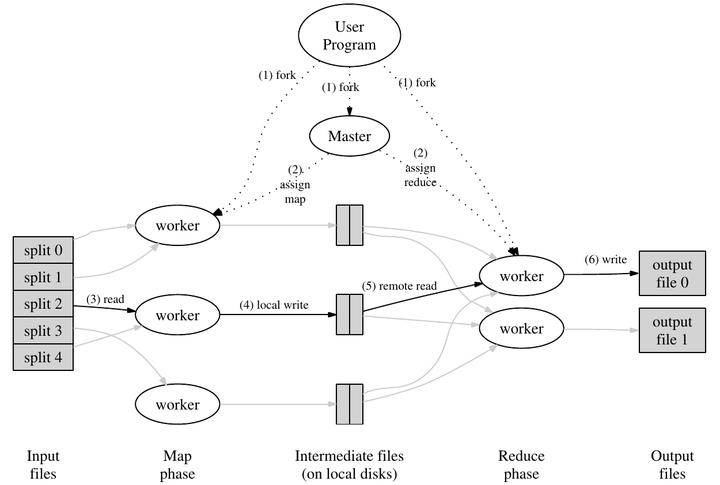
这是论文中讲解MapReduce的流程图,基本上解释清楚了。
输入数据以文件形式进入系统。一些进程运行map任务,拆分了原任务,产生了一些中间体,这些中间体可能以键值对形式存在。一些进程运行了reduce任务,利用中间体产生最终输出。master进程用于分配任务,调整各个worker进程。
输入数据能够产生中间体,这说明原任务是可拆的,也就才有了写成分布式的可能性。若原问题不是可拆的,MapReduce也就无从谈起。
中间体应均匀地分配给各个reduce任务,每个reduce任务整合这些中间体,令中间体个数减少,直至无法再减少,从中整合出最终结果。
输入数据以什么形式进入系统,原任务应如何拆分,中间体如何保存和传输,master和worker之间如何通信和调度,中间体如何转化为最终输出。这些都是设计的考量,没有一定之规。
Lab要求我们做一个对txt文件里的wordcount,那么输入数据就是txt文件,原任务就是对txt文件里的单词进行统计,中间体就是单词和对应的出现次数,最终输出就是单词和对应的出现次数。
示意图如下:
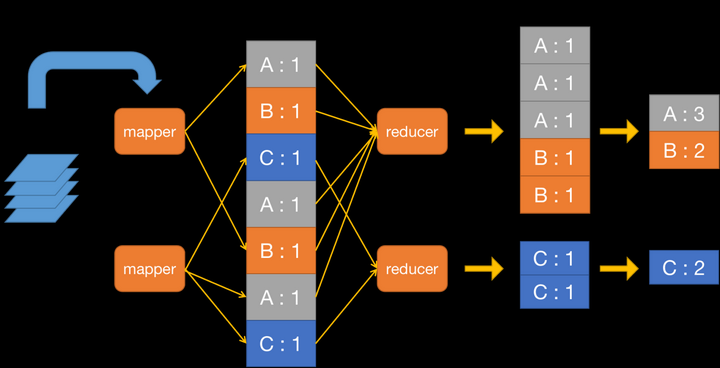
实现细节
queue.go
首先定义一堆结构体(其实也不是首先,在编写过程中会不断地修改和更新结构体,不过在实现一个功能之前必须理清对应的数据结构):
// queue.go
type listNode struct {
data interface{} // data can be any type
next *listNode
prev *listNode
}
type LinkedList struct {
head listNode
count int
}
type BlockQueue struct {
list *LinkedList
cond *sync.Cond
}
由于篇幅限制这里暂时省略了对应的方法,不过重点也不是方法就是了
第一个结构体是链表的节点,第二个结构体是链表,第三个结构体是阻塞队列,阻塞队列是用链表实现的,链表的每个节点都是一个interface{}类型的数据,这样就可以存储任意类型的数据了。
同时阻塞队列还有一个条件变量,用于实现阻塞队列的阻塞功能。
mapset.go
type MapSet struct {
mapbool map[interface{}]bool
count int
}
这个结构体的作用是用于存储键值对,键值对的键是任意类型的,值是bool类型的,这样就可以实现set的功能了。
worker.go
这部分就是重点了,我们这里先不直接抛出代码,先思考一下worker的工作流程。
worker的工作流程如下:
-
从master获取任务
-
执行任务
-
将任务执行结果发送给master
-
重复1-3
-
如果有空闲的worker,master会将任务分配给空闲的worker(才能体现多线程和分布式的优点)这一步暂时取名为Join吧
在获取任务之前,首先应该进行一些初始化,通过下面两个函数,worker能够确定自己在map阶段和reduce阶段的任务是什么,以及自己的id是多少。
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
func keyReduceIndex(key string, nReduce int) int {
// use ihash(key) % NReduce to choose the reduce
return ihash(key) % nReduce
}
然后我们创造一个worker对象,我们接下来的操作都是对这个对象进行操作。
type Aworker struct {
// a struct for worker
mapf func(string, string) []KeyValue
reducef func(string, []string) string
// true: Map
// false: Reduce
MapOrReduce bool
//exit if true
DoneFlag bool
WorkerId int
}
初始化完成后,worker开始向coordinator发送请求,获取任务。
func (worker *Aworker) askMapTask() *MapTaskReply {
/* ask for a map task then return the reply */
args := MapTaskArgs{
WorkerId: worker.WorkerId,
}
reply := MapTaskReply{}
worker.logPrintf("Asking for a map task...\n")
call("Coordinator.GiveMapTask", &args, &reply)
// obtain a worker id
worker.WorkerId = reply.WorkerId
worker.logPrintf("Got a map task, filename: %s, fileId: %v", reply.FileName, reply.FileId)
if reply.FileId == -1 {
// refused to give a task
if reply.DoneFlag {
worker.logPrintf("No more map tasks, switching to reduce tasks...\n")
return nil
} else {
worker.logPrintf("No map tasks available, waiting...\n")
return &reply
}
}
worker.logPrintf("got a map task, filename: %s, fileId: %v\n", reply.FileName, reply.FileId)
return &reply
}
这个函数比较简单,就是向coordinator发送请求,获取任务,如果没有任务就等待,如果有任务就返回任务。没有什么特别需要注意的。
如果coordinator发现所有任务都在进行但是还有空闲的worker,那么就会将任务分配给空闲的worker,这个过程就是Join过程。
func (worker *Aworker) joinMapTask(fileId int) {
// notify coordinator that map task is done, the worker can join another map task
args := MapTaskJoinArgs{
FileId: fileId,
WorkerId: worker.WorkerId,
}
reply := MapTaskJoinReply{}
worker.logPrintf("Joining map task...\n")
call("Coordinator.JoinMapTask", &args, &reply)
if reply.Accepted {
worker.logPrintf("\033[33mAccepted\033[0m to join map task!\n")
} else {
worker.logPrintf("Failed to join map task!\n")
}
}
可以看到,上面几个函数都是通过rpc调用coordinator的函数来实现的。