
CMU 15-445 24Fall 小结 【P1篇】
课程介绍
这门课是CMU的数据库课程,15-445,24Fall版本。课程内容包括数据库系统的设计与实现,涵盖了缓冲池管理、查询处理、事务管理等核心概念。课程采用C++语言进行编程实践,学生需要实现一个简单的缓冲池管理系统。
笔者之前在写23 Fall的版本,但由于自身能动性的原因加上各种外力因素,在通过P0以及P1的Local Test后就暂时搁置了。前几天重新想起这件事想交到Gradescope上时,发现23 Fall的版本已于6月30日停止在线评测了。无奈只能重新下载24 Fall的版本,几乎全部重来。
感谢CMU将课程内容开源,让我这样的菜鸡也能接触到丰富的学习资源和实践机会,遵从CMU将课程资料公开的条件,本文将不会公开代码实现的具体细节。
Task 1:LRU-K Replacement
原理很简单,LRU-K替换算法是LRU算法的扩展,项目文档的原文如下:
When multiple frames have +inf backward k-distance, the replacer evicts the frame with the earliest overall timestamp (i.e., the frame whose least-recent recorded access is the overall least recent access, overall, out of all frames).
先问为什么
LRU 的根本缺陷在于,它基于“太少的信息”做出驱逐决策——它只考虑最近一次访问的时间戳。
这样带来了两个问题:
-
无法区分访问频率: 如果频繁访问的页面(B+Tree 索引根)和不频繁访问的页面的近期访问时间相似,LRU 算法无法区分它们。它可能会仅仅因为更有价值的、使用频率更高的页面不是最近访问的,就将其驱逐。
-
易受大量频繁查询的影响: 执行大型表扫描的查询会污染缓冲池。它会读取许多可能永远不会再使用的页面,但这样做会驱逐驻留在缓存中的潜在有价值的热页面。
因此,需要使用LRU-K来额外维护一个访问历史记录(也即频率),以便更好地做出驱逐决策。
再问怎么做
首先比较容易想的思路是使用两个list来分别维护访问次数大于等于$k$的frame和访问次数小于$k$的frame。
在进行驱逐时,自然是优先从访问次数未达到$k$的frame中选择。
还有一个细节是,当访问次数达到$k$时,需要将该frame从未达到$k$的list中删除,并添加到已达到$k$的list中。(当然一定有其他更好的实现)
在多线程的环境下,逻辑上最先进list的frame不一定是时间戳最老的,因此如果直接使用list::front()来获取最老的时间戳会在后面的测试出错。因此还是得遍历寻找最老的时间戳。
一个比较容易想到的优化是使用优先队列priority_queue来维护两个列表里的的frame,这样可以在$O(logN)$的时间复杂度内获取最老的时间戳。
当然,为了防止Data Race,我们需要在每个操作的开始加一把大锁。
Task 2:Disk Scheduler
这个部分主要是熟悉异步IO的使用,以及如何在多线程环境下进行磁盘调度,是本p里面最简单的部分。
-
课程已经提前实现好了一个
Channel类,成员变量是request_queue_,使用std::condition_variable来实现异步IO的等待和通知,用于在调度线程和工作线程之间传递请求。 -
Schedule(DiskRequest r)负责接收一个DiskRequest,并将其放入request_queue_中。 -
StartWorkerThread()启动一个工作线程,该线程会不断从request_queue_中取出请求并处理。
在析构函数里面可以看到,DiskScheduler 在销毁时会向队列里放一个std::nullopt,以通知工作线程退出,那么我们只需要在循环里面检测到这个信号跳出就可以了。
Task 3:Buffer Pool Manager
这个部分是整个P1的核心,需要将前面实现的LRU-K替换算法和磁盘调度器结合起来,完成缓冲池管理器的实现。
首先最该做的事情是了解项目结构,我们需要做什么以及怎么去做。
BPM 的核心职责就是透明地管理这个缓存 。当系统的其他部分需要一个 page_id 对应的页面时,它向 BPM 发出请求。它不关心这个页面当前是否在内存中,或者需要从磁盘读取。BPM 负责处理所有这些细节,对上层屏蔽了底层的复杂性。
一个frame在BPM中有以下几种状态:
-
Free:它不包含任何有效数据页,其
page_id为INVALID_PAGE_ID。 -
Cached && Pinned:帧中包含一个有效的数据页。
page_table_中有page_id -> frame_id的映射。页面的pin_count > 0。这意味着有线程正在使用这个页面,BPM 绝对不能驱逐它。此时,它也不能在replacer_中。 -
Cached && Unpinned: 帧中包含一个有效的数据页。
page_table_中有映射。页面的pin_count == 0。没有线程在使用它,它是一个可以被驱逐的候选者。此时,它的frame_id必须在replacer_中,并被标记为evictable。
由于Page_Guard的加入,个人觉得24的Task 3要考虑的东西比23的多了很多。
在旧版的实现中,我们直接操作一个 Page* 数组,新版则引入了 FrameHeader 结构体来封装 Page* 和其他元数据。
在旧版中,FetchPage() 返回一个裸指针 Page*,调用者有责任在用完后手动调用 UnpinPage(),新版则使用 PageGuard 类来自动管理页面的生命周期,确保在使用完页面后页面的pin_count_自动减少。
这也就意味着,我们几乎需要同时实现 BufferPoolManager 和 PageGuard。
先讲一讲个人对PageGuard实现的理解
PageGuard
构造函数 (ReadPageGuard(...), WritePageGuard(...))
这个构造函数由BPM在成功获取并锁定一个页面后调用。将从BPM传入的参数(page_id, frame, replacer, bpm_latch)通过 std::move 保存到自身的成员变量中。同时,设置一个内部标志位,表示这是一个有效的、持有资源的Guard。
Move 语义 (&& 构造函数和赋值运算符)
详细的值类别讲解可以参考叔叔的这篇文章
这里暂时只讲此project里面的用处:一个 PageGuard 代表了对一个页面的一次锁定。绝不能允许两个Guard对象认为它们同时拥有同一次锁定,否则当它们都被销毁时,会导致页面被解钉两次,引发未知的后果。Move语义确保了“所有权”的唯一性。
Drop() 方法
RAII思想的体现,这是 PageGuard 中最关键的方法,它在Guard被销毁时自动调用,负责归还资源。
首先它应该是幂等的,也就是说我们需要在最开始检查Guard的标志位。之后就是释放资源,比如pin_count_的减少和后面会提到的对FrameHeader实例的解锁,如果发现pin_count_已经为0了,这意味着你是最后一个释放这个页面的线程,,需要与replacer_进行交互,通知它可以驱逐这个页面。
BufferPoolManager
其他几个函数的实现都较为简单,与23 Fall版本的实现差别不大,这里重点讲一下最复杂也是最核心的CheckedReadPage / CheckedWritePage函数。
稍微思考后能设计出大致的流程应该如下:
- 加一把大锁
- 在
page_table_中查找page_id - 如果找到了,说明页面已经在内存中(cache hit),更新元数据,返回对应的
PageGuard。 - 没找到,则进入缓存未命中(cache miss)的处理流程,与
replacer_交互,尝试是否能获取到一个空闲/可驱逐的frame。- 如果是空闲的
frame,则直接使用它。 - 如果是可驱逐的
frame,则需要先检查它的is_dirty_标志位,如果是脏页需要先异步写回磁盘。
- 如果是空闲的
- 如果以上步骤都失败了,说明缓冲池已满且所有页都被钉住,直接返回
std::nullopt。
以这样的思路应该可以完美地通过23 Fall的测试用例。
但可惜24 Fall的并发部分略微复杂和健全一点,在23 Fall的实现中,我们只需要关心 BPM 自身的大锁,在每次操作的最开头使用std::lock_guard 来加锁,其会在生命周期结束(即函数返回)时自动解锁。
但在24 Fall的实现中,FrameHeader 有自己单独的页级锁 rwlatch_,它的生命周期并不归 BPM 管理,这意味着我们需要单独考虑 BPM 的大锁 bpm_latch_ 和 FrameHeader 的 rwlatch_ 的加锁/解锁顺序。
首先考虑一下页级锁和pin_count_的顺序
pin_count_ 的值决定了页面是否可以被驱逐。只有当 pin_count_ == 0 时,页面才可以被驱逐。
两者的关系应该是这样:
(CheckedXXXPage函数) pin_count_ 增加 → rwlatch_ 加锁 → (Drop()函数)rwlatch_ 解锁 → pin_count_ 减少。
从设计直觉上很好理解,先获取的资源后释放,后获取的资源先释放(Last-In, First-Out, LIFO),如果一个对象包含其他遵循RAII的对象成员,它们的构造和析构顺序也是栈式的。
那么为什么pin_count_的改变要在rwlatch_加锁之前呢?
因为pin_count_ 的值决定了页面是否可以被驱逐,这直接决定了此页面在BPM里面是以什么状态出现的,如果先加锁后,pin_count_ 的值还没来得及改变就被其他线程检测到为0了,那么就会导致这个页面有可能被驱逐,偏离原来的设计本意。
然后考虑一下大锁和页级锁的顺序
一个很简单的思路是,在CheckedXXXPage函数中,先加大锁,等到获取到FrameHeader后,再对这个frame实例加上页级锁。
然后你激动地运行测试,发现 Terminal 的输出停在了这个地方::
[ RUN ] BufferPoolManagerTest.DeadlockTest
恭喜你,程序死锁了。
课程非常贴心地把这里的测试代码给出来了,我们来看看发生了什么。
auto pid0 = bpm->NewPage();
auto pid1 = bpm->NewPage();
auto guard0 = bpm->WritePage(pid0);
// A crude way of synchronizing threads, but works for this small case.
std::atomic<bool> start = false;
auto child = std::thread([&]() {
// Acknowledge that we can begin the test.
start.store(true);
// Attempt to write to page 0.
auto guard0 = bpm->WritePage(pid0);
});
// Wait for the other thread to begin before we start the test.
while (!start.load()) {
}
// Make the other thread wait for a bit.
// This mimics the main thread doing some work while holding the write latch on page 0.
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
// If your latching mechanism is incorrect, the next line of code will deadlock.
// Think about what might happen if you hold a certain "all-encompassing" latch for too long...
// While holding page 0, take the latch on page 1.
auto guard1 = bpm->WritePage(pid1);
复盘一下这里是怎么进入到死锁局面的:
-
$T0$ 获取
bpm_latch_,然后获取 $pid0$ 的rwlatch_,最后释放bpm_latch_,返回 Guard。此时,$T0$ 只持有 $pid0$ 的rwlatch_。 -
$T1$ (子): 调用
WritePage(pid0)。
-
它成功获取了全局
bpm_latch_。 -
然后它尝试获取 $pid0$ 的
rwlatch_。但这个锁被 $T0$ 持有,所以 $T1$ 在这里被阻塞,并且它死死地攥着全局bpm_latch_不放。
- $T0$ (主): 睡醒后,调用
WritePage(pid1)。
-
这个操作需要通过BPM,因此它尝试获取全局
bpm_latch_。 -
但这个锁此刻正被阻塞的 $T1$ 攥在手里。所以 $T0$ 在这里也被阻塞了。
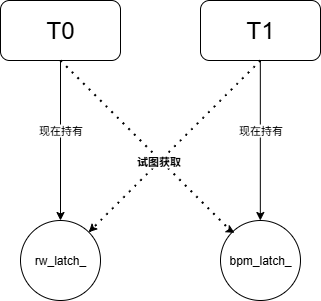
两个线程互相等待对方持有的资源,形成了经典的 AB-BA 死锁。整个程序因此永久挂起。
因此,我们不应该在持有一个粗粒度锁(bpm_latch_)的同时去获取一个细粒度锁(rwlatch_)。
综合以上两点,我们得出初步的加锁流程:
-
获取粗粒度的
bpm_latch_。 -
在
page_table_中找到对应的帧。(必须受bpm_latch_保护) -
立刻增加
pin_count_。确保它不会被我们在Task1写的replacer_驱逐。 -
释放粗粒度的
bpm_latch_。 -
在没有持有全局锁的情况下,去获取细粒度的
rwlatch_。这个操作可能会阻塞,但不会影响其他线程操作BPM的其他页面。 -
最后,返回一个
PageGuard,它会在析构时自动调用Drop()方法,在析构时,要先解锁rwlatch_,再减少pin_count_。
那现在总能通过测试了吧?
当你这样想的时候你就会发现代码挂在了死锁测试的下一个测试
[ RUN ] BufferPoolManagerTest.EvictableTest
Value of: bpm->CheckedReadPage(loser_pid).has_value()
Actual: true
Expected: false
[ FAILED ] BufferPoolManagerTest.EvictableTest (1135 ms)
EvictableTest
先看一下这个测试在做什么:
for (size_t i = 0; i < rounds; i++) {
std::mutex mutex;
std::condition_variable cv;
// This signal tells the readers that they can start reading after the main thread has already taken the read latch.
bool signal = false;
// This page will be loaded into the only available frame.
page_id_t winner_pid = bpm->NewPage();
// We will attempt to load this page into the occupied frame, and it should fail every time.
page_id_t loser_pid = bpm->NewPage();
std::vector<std::thread> readers;
for (size_t j = 0; j < num_readers; j++) {
readers.emplace_back([&]() {
std::unique_lock<std::mutex> lock(mutex);
// Wait until the main thread has taken a read latch on the page.
while (!signal) {
cv.wait(lock);
}
// Read the page in shared mode.
auto read_guard = bpm->ReadPage(winner_pid);
// Since the only frame is pinned, no thread should be able to bring in a new page.
ASSERT_FALSE(bpm->CheckedReadPage(loser_pid).has_value());
});
}
std::unique_lock<std::mutex> lock(mutex);
if (i % 2 == 0) {
// Take the read latch on the page and pin it.
auto read_guard = bpm->ReadPage(winner_pid);
// Wake up all of the readers.
signal = true;
cv.notify_all();
lock.unlock();
// Allow other threads to read.
read_guard.Drop();
} else {
// Take the read latch on the page and pin it.
auto write_guard = bpm->WritePage(winner_pid);
// Wake up all of the readers.
signal = true;
cv.notify_all();
lock.unlock();
// Allow other threads to read.
write_guard.Drop();
}
for (size_t i = 0; i < num_readers; i++) {
readers[i].join();
}
}
-
测试首先将缓冲池的大小设置为只有 $1$ 个帧。这意味着缓冲池在任何时候最多只能容纳一个页面。
-
然后一个
winner_pid占用了唯一的名额,随后$8$个线程同时读取winner_pid,导致它的pin_count_远大于$0$。 -
在此期间,测试试图加载一个
loser_pid,它应该失败,因为缓冲池已满,要加载它,就必须换出winner_pid,但winner_pid被钉住了,不能换出。
因此可以看到,我们在持有 BPM 的大锁时,还需要更新其他的元数据(page_table_, is_dirty_等),pin_count_ 的变化与 SetEvictable 在其他线程看来必须保持原子性。当这些所有该 BPM 做的事都做完以后,BPM 此时才能安全地将 bpm_latch_ 解锁。
所以综上,我们能得到一个完整的加锁流程:
-
获取粗粒度的
bpm_latch_。 -
在
page_table_中找到对应的帧。(必须受bpm_latch_保护) -
立刻增加
pin_count_。确保它不会被我们在Task1写的replacer_驱逐。 -
更新其他元数据(
page_table_,is_dirty_等),同时与replacer_交互,记录访问和标记为不可驱逐。 -
释放粗粒度的
bpm_latch_。 -
在没有持有全局锁的情况下,去获取细粒度的
rwlatch_。这个操作可能会阻塞,但不会影响其他线程操作BPM的其他页面。 -
(如果cache miss)使用 promise 和 future 异步地从磁盘读取页面到
frame中。 -
最后,返回一个
PageGuard,它会在析构时自动调用Drop()方法,在析构时,要先解锁rwlatch_,再减少pin_count_。
这里我最早的实现写的很丑,还用了一个无限循环,在其中try_lock() 和 std::this_thread::yield() 等来避免死锁。但后来发现 BPM 的解锁时机可以放在较后面的时机,只要保证在获取 rwlatch_ 之前,所有的元数据都已经更新完毕即可。
但其实经过几次测试,我发现有一种特定的实现,在 Cache Miss 的路径上,当持有 BPM 的大锁时,再去尝试获取 rwlatch_ 也不会死锁。
这似乎有悖前面的结论,但终版代码确实能通过 Gradescope 的所有测试。
如果排除掉 Gradescope 测试用例太弱的话,原因应该是这样的:
-
在 Cache Miss 时,BPM 会与
replacer_交互,获得了一个牺牲品页面,但在找到这个页面的后,我们需要保证其是全新的,才能供我们现在使用。 -
这里涉及到另一个细节:如果驱逐途中发现,页面是脏页,我们需要先将其异步写回磁盘,并且重置其所有元数据。这里的实现马上将其从
page_table_中也删除掉了。 -
因此,对于其他线程来说,当前这个线程获取到的 frame 要么是“不存在的”(不在
page_table_中),要么属于一个已经被逻辑上删除的旧页面。也自然不会有线程尝试获取这个页面的rwlatch_了。
个人觉得这种实现应该不是 best practice,但其确实能通过所有测试,可能得在后续的优化环节思考怎么改进了,也欢迎大家评论区交流。